AWS Machine Learning Blog
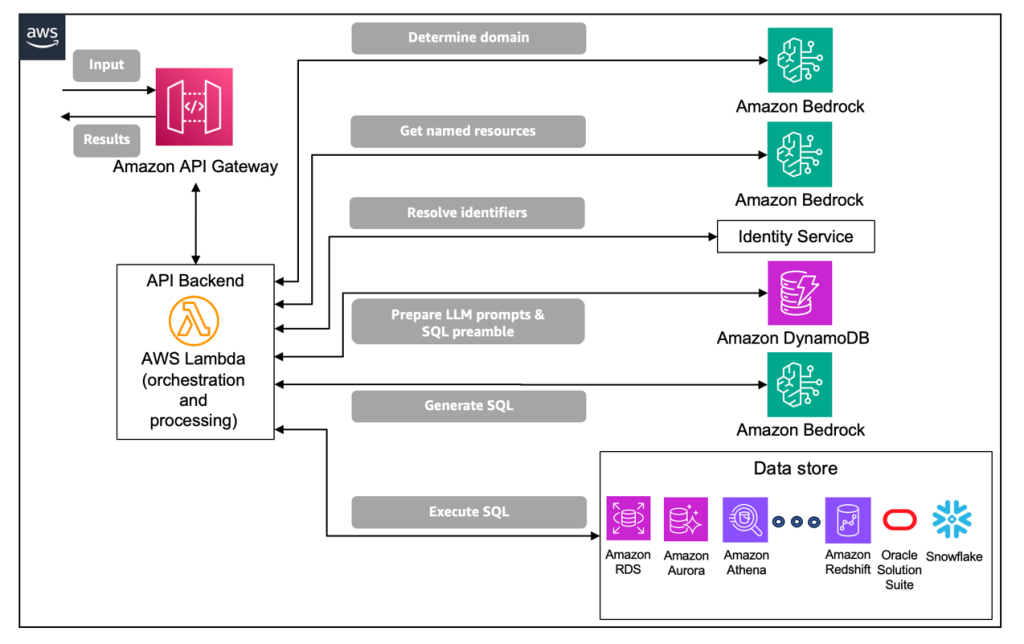
Enterprise-grade natural language to SQL generation using LLMs: Balancing accuracy, latency, and scale
In this post, the AWS and Cisco teams unveil a new methodical approach that addresses the challenges of enterprise-grade SQL generation. The teams were able to reduce the complexity of the NL2SQL process while delivering higher accuracy and better overall performance.

AWS Field Experience reduced cost and delivered low latency and high performance with Amazon Nova Lite foundation model
The AFX team’s product migration to the Nova Lite model has delivered tangible enterprise value by enhancing sales workflows. By migrating to the Amazon Nova Lite model, the team has not only achieved significant cost savings and reduced latency, but has also empowered sellers with a leading intelligent and reliable solution.
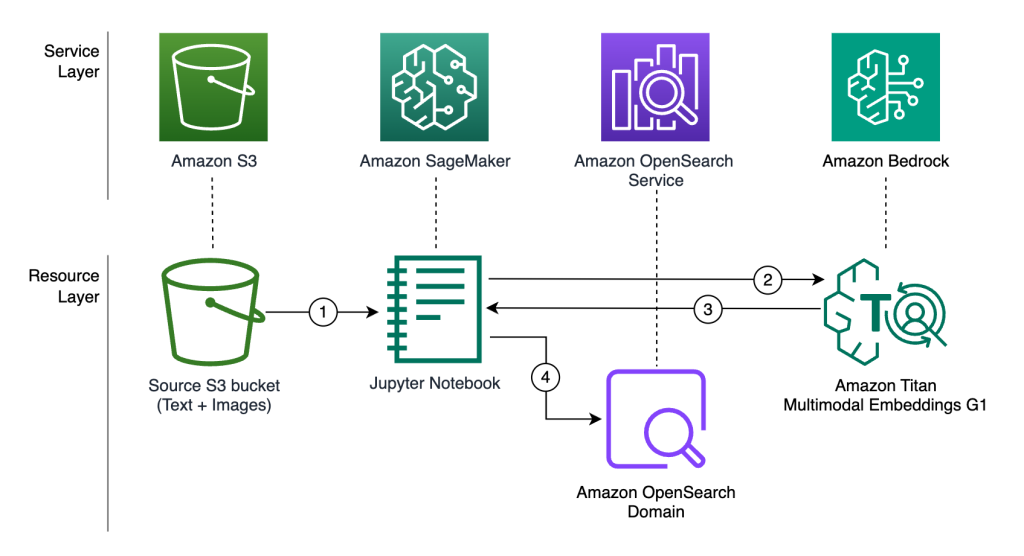
Combine keyword and semantic search for text and images using Amazon Bedrock and Amazon OpenSearch Service
In this post, we walk you through how to build a hybrid search solution using OpenSearch Service powered by multimodal embeddings from the Amazon Titan Multimodal Embeddings G1 model through Amazon Bedrock. This solution demonstrates how you can enable users to submit both text and images as queries to retrieve relevant results from a sample retail image dataset.

Build an AI-powered document processing platform with open source NER model and LLM on Amazon SageMaker
In this post, we discuss how you can build an AI-powered document processing platform with open source NER and LLMs on SageMaker.
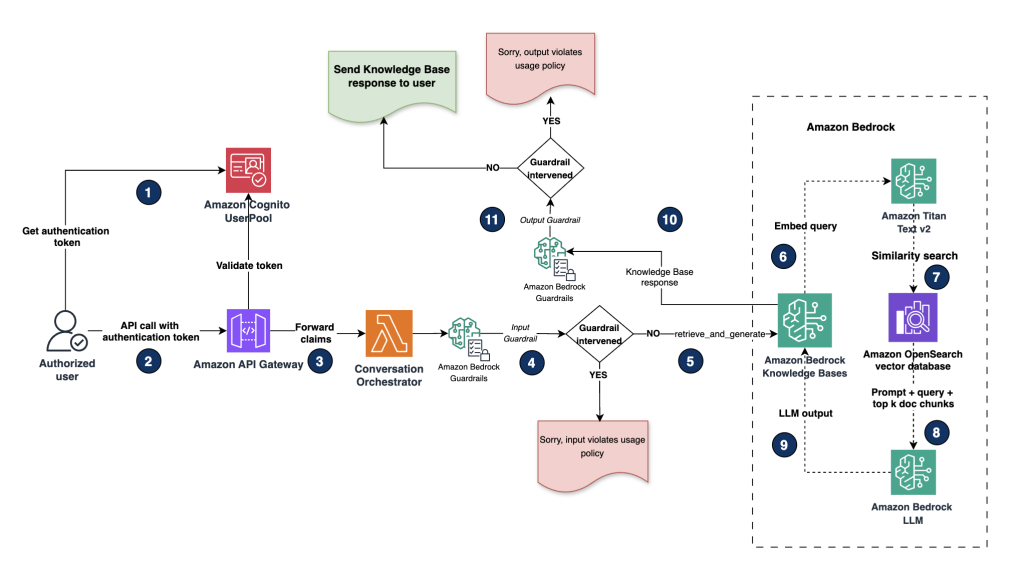
Protect sensitive data in RAG applications with Amazon Bedrock
In this post, we explore two approaches for securing sensitive data in RAG applications using Amazon Bedrock. The first approach focused on identifying and redacting sensitive data before ingestion into an Amazon Bedrock knowledge base, and the second demonstrated a fine-grained RBAC pattern for managing access to sensitive information during retrieval. These solutions represent just two possible approaches among many for securing sensitive data in generative AI applications.

Supercharge your LLM performance with Amazon SageMaker Large Model Inference container v15
Today, we’re excited to announce the launch of Amazon SageMaker Large Model Inference (LMI) container v15, powered by vLLM 0.8.4 with support for the vLLM V1 engine. This release introduces significant performance improvements, expanded model compatibility with multimodality (that is, the ability to understand and analyze text-to-text, images-to-text, and text-to-images data), and provides built-in integration with vLLM to help you seamlessly deploy and serve large language models (LLMs) with the highest performance at scale.
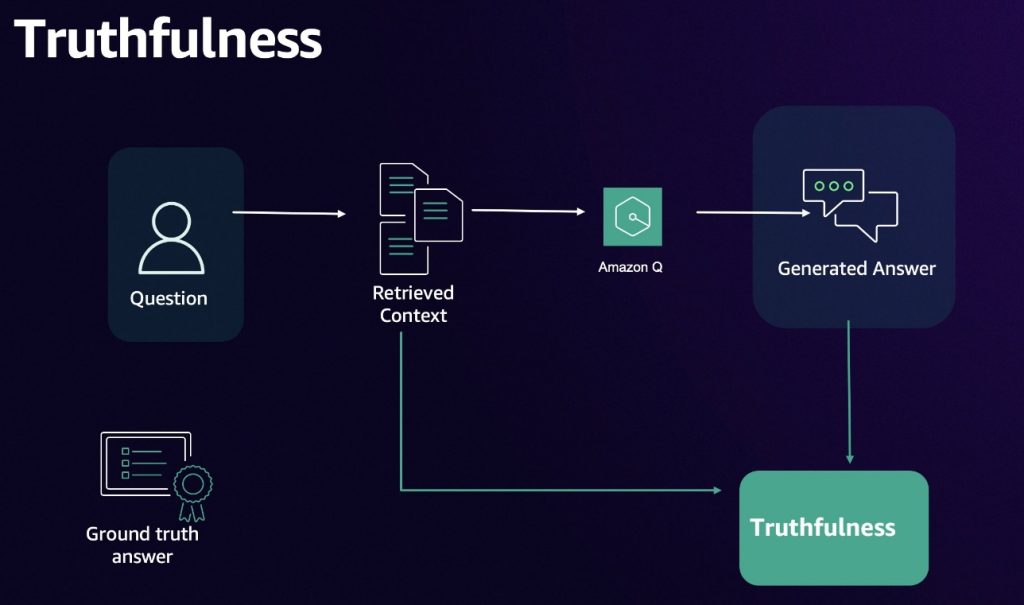
Accuracy evaluation framework for Amazon Q Business – Part 2
In the first post of this series, we introduced a comprehensive evaluation framework for Amazon Q Business, a fully managed Retrieval Augmented Generation (RAG) solution that uses your company’s proprietary data without the complexity of managing large language models (LLMs). The first post focused on selecting appropriate use cases, preparing data, and implementing metrics to […]

Use Amazon Bedrock Intelligent Prompt Routing for cost and latency benefits
Today, we’re happy to announce the general availability of Amazon Bedrock Intelligent Prompt Routing. In this blog post, we detail various highlights from our internal testing, how you can get started, and point out some caveats and best practices. We encourage you to incorporate Amazon Bedrock Intelligent Prompt Routing into your new and existing generative AI applications.
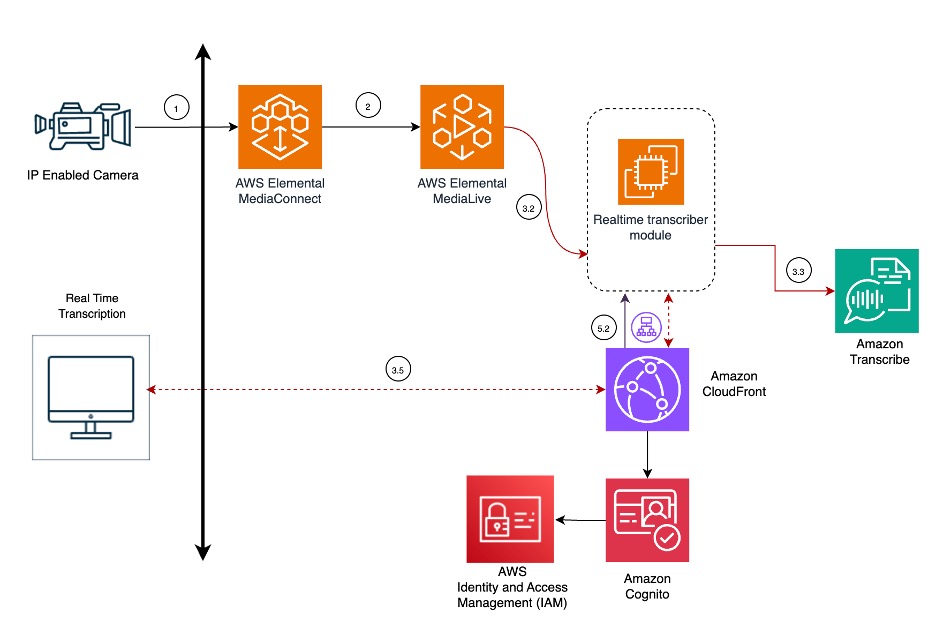
How Infosys improved accessibility for Event Knowledge using Amazon Nova Pro, Amazon Bedrock and Amazon Elemental Media Services
In this post, we explore how Infosys developed Infosys Event AI to unlock the insights generated from events and conferences. Through its suite of features—including real-time transcription, intelligent summaries, and an interactive chat assistant—Infosys Event AI makes event knowledge accessible and provides an immersive engagement solution for the attendees, during and after the event.

Amazon Bedrock Prompt Optimization Drives LLM Applications Innovation for Yuewen Group
Today, we are excited to announce the availability of Prompt Optimization on Amazon Bedrock. With this capability, you can now optimize your prompts for several use cases with a single API call or a click of a button on the Amazon Bedrock console. In this blog post, we discuss how Prompt Optimization improves the performance of large language models (LLMs) for intelligent text processing task in Yuewen Group.